什么是重复(Duplicate Content)的内容?
重复的内容是指,相同的内容出现在网际网路上多个地方。 「一个地方」被定义为唯一网址(URL),因此如果相同的内容出现在多个网址上,则表示您的网站内容重复。
虽然在技术上不是一种惩罚,但重复的内容有时还会影响搜索引擎的排名。 如Google所称,在互联网上的多个位置存在多个“明显相似”的内容时,搜索引擎可能很难决定哪个版本与给定的搜索查询更相关。
为什么重复的内容很重要?
以搜索引擎来说
重复的内容可能会对搜索引擎提出三个主要问题:
他们不知道哪个版本包含/不包括在他们的索引中。
他们不知道是否将链接指标(网站信任评分,网站权威评分,文字链接,反向链接价值…等)指哪一个页面,或保持它为多个分开的版本。
他们不知道要为查询结果排名哪个网页版本。
以网站所有者来说
当存在重复的内容时,网站所有者可能遭受排名和流量损失,这些损失通常来自两个主要问题:
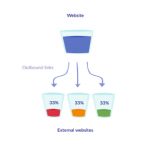
为了提供最佳搜索体验,搜索引擎很少会显示同一内容的多个网页版本,因此最有可能是,被迫选择其中一个版本,这会稀释了其他版本的曝光度。
链接公平可能会被进一步稀释,因为其他网站也必须在重复之间进行选择。 而不是所有的入站链接指向一个内容,他们链接到多个片断,在重复之间传播链接公平。 由于入站链接是排名因素,因此这会影响一段内容的搜索可见性。
重复内容如何发生的?
在绝大多数情况下,网站所有者不会故意创建重复的内容,但是,这并不表示不会发生,实际上据估计,高达29%的网页内容实际上是重复的内容!
让我们来看看一些最常见的重复内容是无意中创建的:
1.网址变体
网址参数(如点击跟踪和某些分析代码)可能会导致重复的内容问题,这个可能性的问题,不仅仅会由参数本身产生,还包括这些参数在URL中出现的顺序。
程序码范例
https://www.benny.vip/?p=446 重复于
https://www.benny.vip/446.html
https://www.benny.vip/?p=436
重复于 https://www.benny.vip/436.html
同样,session ID是常见的重复内容发生原因,当浏览网站的每一个用户,网址参数URL中有不同session ID时,就会发生这种情况。
当多个版本的网页被索引时,友善打印的内容也会导致重复的内容问题。
https://www.benny.vip/?p=429
重复于 https://www.benny.vip/429.html
这里的一个警讯是,可能的话,比较好的避免方式是,不添加URL参数或URL的替代版本(其中包含的信息通常可以通过scripts传递)。
HTTP与HTTPS或WWW与非WWW页面
如果您的网站在“www.site.com”和“site.com”上有不同的版本(带有或不带有“www”),并且在这两个版本中都有相同的内容,你应该已经有创建了每个版本的重复网页。
这同样适用于在http://和https://上维护版本的网站。如果网页的两个版本都是存在的并且可以被搜索引擎可以检索的,应该也是会遇到重复的内容问题。
撷取或是拷贝内容
内容不仅包括部落格文章或编辑内容,还包括产品讯息网页,在自己的网站上重新发布您的部落格内容,有可能是一个更为常见的重复内容来源,但电子商务网站也存在一个共同的问题:产品资讯,如果很多不同的网站出售相同的商品,而且他们都使用制造商对这些商品的描述,那么相同的内容就会出现在网路上的多个位置。
如何解决重复的内容问题
修复重复内容的主要宗旨,就是指定哪个内容是【最正确的】。
只要网站上的内容可以在多个网址上找到,就应该对搜索引擎进行规范化处理,我们来看看三种主要方法:
使用301重定向到正确的URL,rel = “canonical ” 属性,或使用 Google Search Console中的参数处理工具。
301转址
在许多情况下,处理重复内容的最佳方法是设置301转址从「重复」网页到原始内容网页。
当多个排名好的网页被合并成一个页面时,他们不仅不再相互竞争,他们也创造一个更强的相关性和整体流行讯息,这将对「正确」页面排名良好的能力产生良好的影响。
Rel=”canonical”
处理重复内容的另一个选项是使用rel = canonical属性。 这告诉搜索引擎一个特定的网页应该被视为一个指定的URL副本,所有的链接、内容指标和搜索引擎将导入于这个网页的【排名权重】并且应该被记录到指定的URL。
rel =“canonical”属性是网页HTML表头的一部分,如下:
程序码范例
<head >
…[其他程序码]…
<link href= “来源网页链接 ” rel=”canonical ” / >
…[其他程序码]…
</head >
将 rel = canonical 属性添加到每个重复的网页的HTML表头上面,将上述范例“来源网页链接”部分由你的原始网页的替换链接(请保留引号),该属性传递与301重定向相同数量的链接权限(排名能力),并且由于它在网页(而不是服务器)上修复,所以通常需要较少的时间执行修复。
Meta Robots Noindex
在处理重复内容时,使用Meta Robots标签是很有用的,当放入“noindex,follow”时。 通常称为Meta Noindex,Follow和技术上称为content =“noindex,follow”添加这些Meta Robots标记到的每个单独页面的HTML头部,应该可以从搜索引擎索引中排除。
程序码范例
<head >
…[其他程序码]…
<meta name= “robots ” content= “noindex,follow ” >
…[其他程序码]…
</head >
上述 Meta Robots 标签允许搜索引擎抓取网页上的链接,但不让这些链接包含在该索引中。
有一点非常重要,即使您要求Google不要抓取重复的网页,Google仍然有可能将其编入索引,因为Google有明确提醒您不要在您的网站上限制对重复内容的抓取访问。(搜索引擎希望能够看到你的代码中可能的错误,是因为希望可以排除意外因素,这使得他们可以在不确定的状况下做出一个「可能是自动的」“呼叫判定”。
使用Meta Robots 解决与分页有关的重复内容问题的一个好的方式。
Google Search Console 中的主网域和参数处理
Google Search Console可让您设定网站的主要网域( https://benny.vip/ 替代为 https://www.benny.vip/ ) 与指定Googlebot 可能使用不同的方式抓取各种网址参数(参数处理)。
Google根据您的URL结构和重复内容问题的原因,设置您的主选域名称或参数处理(或两者都设置)可能会提供一个解决方案。
使用参数处理作为处理重复内容的主要方法的主要缺点是您所做的更改仅适用于Google,使用Google Search Console的任何规则都不会影响Bing或任何其他搜索引擎的抓取工具如何解读您的网站; 除了调整Search Console中的设置之外,您还需要将网站站长工具用于其他搜索引擎。。
处理重复内容的其他方法
在整个网站内部进行链接时保持一致,例如如果网站管理员确定域名的版本为www.example.com/,则所有内部链接应该转到http://www.example.com/example而不是http://example.com/ 页面(注意缺少www)。
在组合文章内容时,请确保组合网页将正确链接导回原始内容,而不是使用URL变体方式。
添加一个额外的保护措施,以防止文章内容被盗取并且被窃取SEO权重,明智的做法是添加一个自我指向的 rel = canonical 链接到您的现有网页,这是一个canonical的属性,指向它已经在的URL,重点是挫败文章盗取者的努力。
虽然并不是所有的文章盗取都会经由来源代码(完整的HTML代码),但有些会,对于那些有盗取来源代码的,只要有使用 rel = canonical标签将确保您的网站的版本被认为是“原始”内容。